ReVoice Results & Samples
Abstract
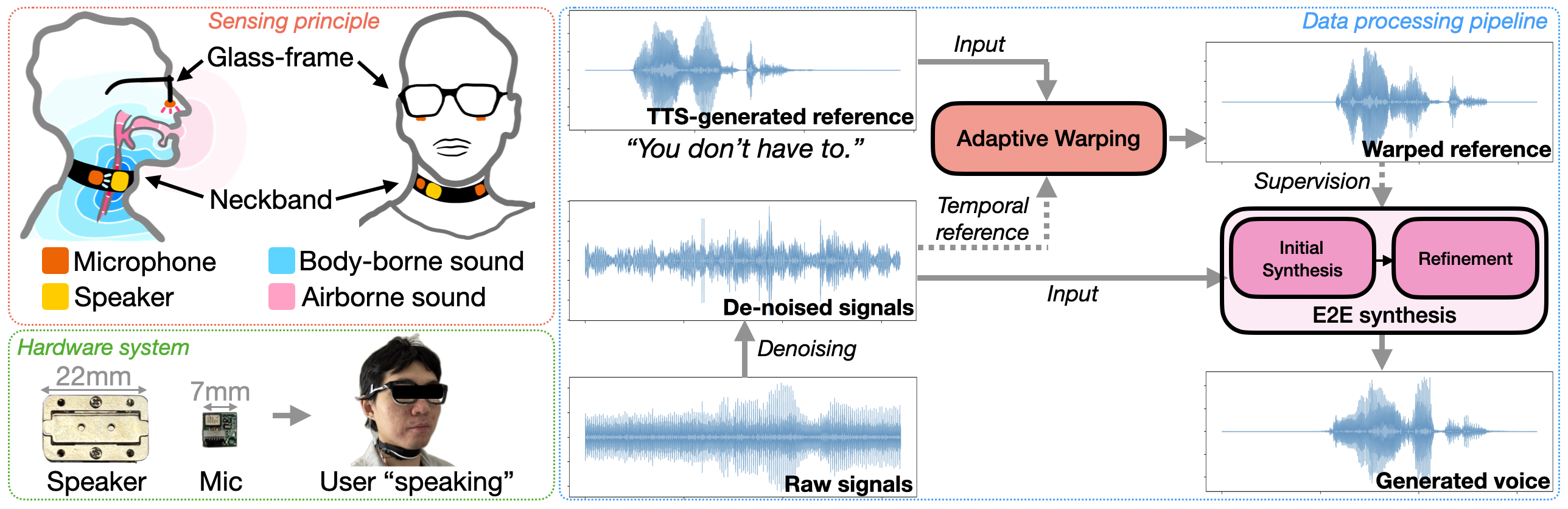
Total laryngectomy, a necessary procedure for advanced laryngeal cancer, results in the permanent loss of natural voice, profoundly affecting communication and quality of life for laryngectomees. Existing standard-of-care voice restoration methods face significant limitations, often requiring expensive and invasive surgical procedure (e.g., tracheoesophageal puncture, TEP), which are not suitable for all laryngectomees, or producing suboptimal speech quality (e.g., esophageal speech, ES, and electrolarynx, EL). We introduce ReVoice, a non-invasive and affordable wearable system that invents a novel AI-powered active acoustic sensing method to restore natural and intelligible voice for laryngectomees. ReVoice uses a neck-worn bone conduction actuator to gently probe the vocal tract with sound waves and capture the modulated acoustic signals representing silent articulatory movements using microphones on a neckband and eyeglass frame. These captured acoustic signals are then analyzed by an end-to-end generative AI pipeline to directly synthesize highly intelligible speech with natural temporal dynamics. We evaluated ReVoice with 26 participants, including 11 laryngectomees, which demonstrated its promising ability to generate natural and intelligible speech for continuously spoken, unseen sentences, offering significant improvements over existing solutions in terms of form factor obtrusiveness, social acceptance, speech quality and evaluation robustness. ReVoice combines active acoustic sensing with cutting-edge generative AI, demonstrating great potential for an accessible, affordable, and high-performance voice restoration solution for laryngectomees.
Audio & Spectrogram Comparisons
Compared with traditional voice recovery practices, ReVoice provides superior voice quality while being non-invasive. The following compares the voice generated using an electrolarynx and those generated by ReVoice.
Electro-larynx Generated Voice
This is the sound produced by a standard electrolarynx, a common device used for voice restoration. Although non-invasive, it often has a robotic quality due to its electronically generated tone.

ReVoice: Raw Sensor Signal
This represents the raw audio signal captured by the ReVoice microphones during silent articulation, before any processing. It contains the modulated sound waves that is hardly legible.
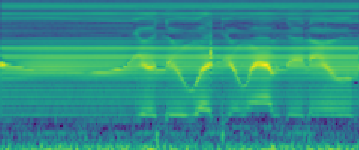
ReVoice: De-noised Sensor Signal
The raw sensor signal after applying de-noising algorithms. This step aims to remove the buzzing noise and prepare for further processing.
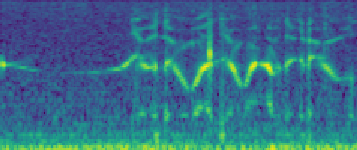
ReVoice: AI Generated Voice
The final synthesized speech produced by the ReVoice AI pipeline from the processed sensor signals. This demonstrates the system's ability to synthesize audible speech for laryngectomees.
Summary of Performance
The table below summarizes the performance metrics for different participants, categorized into Laryngectomees and Voiced groups. In total, there are 15 Voiced participants and 11 Laryngectomee participants. Each participant finished 20 data collection sessions, indexed from 00 to 19. In each session, they were instructed to wear the ReVoice device, and utter 100 sentences silently. Remounting of the device was conducted after session 09 and 17. Sessions 18-19 (used for testing) only contained sentences that never appeared in previous sessions. Click on a participant's name to listen to mode samples. Click (?) for metric or group info.
| Metric |
|---|